CapsNet基本结构
参考CapsNet的论文,提出的基本结构如下所示:
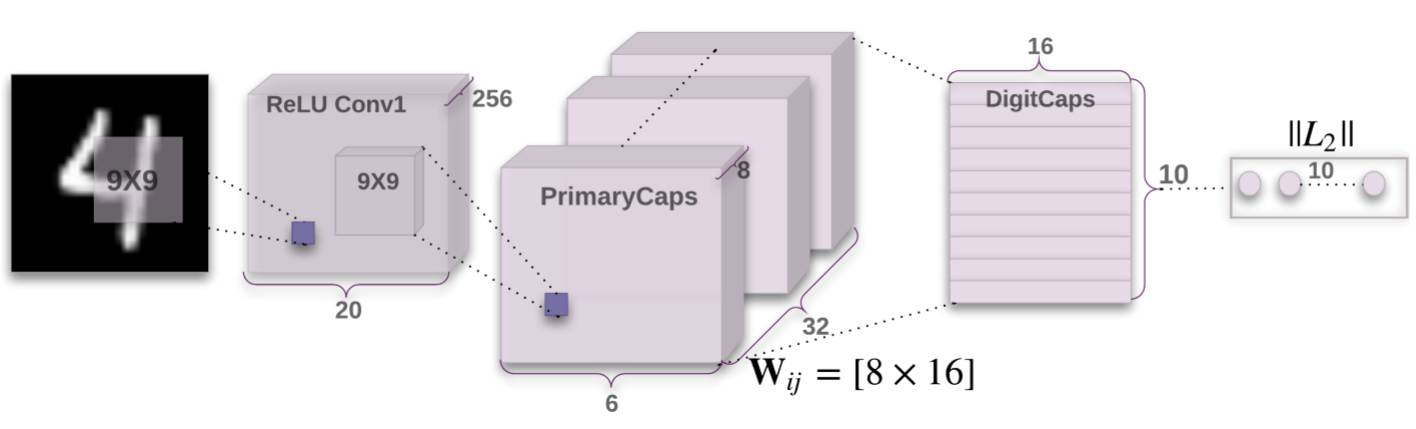
可以看出,CapsNet的基本结构如下所示:
- 普通卷积层Conv1:基本的卷积层,感受野较大,达到了9x9
- 预胶囊层PrimaryCaps:为胶囊层准备,运算为卷积运算,最终输出为[batch,caps_num,caps_length]的三维数据:
- batch为批大小
- caps_num为胶囊的数量
- caps_length为每个胶囊的长度(每个胶囊为一个向量,该向量包括caps_length个分量)
- 胶囊层DigitCaps:胶囊层,目的是代替最后一层全连接层,输出为10个胶囊
代码实现
胶囊相关组件
激活函数Squash
胶囊网络有特有的激活函数Squash函数:
其中输入为S胶囊,该激活函数可以将胶囊的长度压缩,代码实现如下:
1 | def squash(inputs, axis=-1): |
其中:
norm = torch.norm(inputs, p=2, dim=axis, keepdim=True)计算输入胶囊的长度,p=2表示计算的是二范数,keepdim=True表示保持原有的空间形状。scale = norm**2 / (1 + norm**2) / (norm + 1e-8)计算缩放因子,即$ \cfrac{||S||^2}{1+||S||^2} \cdot \cfrac{1}{||S||}$return scale * inputs完成计算
预胶囊层PrimaryCaps
1 | class PrimaryCapsule(nn.Module): |
预胶囊层使用卷积层实现,其前向传播包括三个部分:
outputs = self.conv2d(x):对输入进行卷积处理,这一步output的形状是[batch,out_channels,p_w,p_h]outputs = outputs.view(x.size(0), -1, self.dim_caps):将4D的卷积输出变为3D的胶囊输出形式,output的形状为[batch,caps_num,dim_caps],其中caps_num为胶囊数量,可自动计算;dim_caps为胶囊长度,需要预先指定。return squash(outputs):激活函数,并返回激活后的胶囊
胶囊层DigitCaps
参数定义
1 | def __init__(self, in_num_caps, in_dim_caps, out_num_caps, out_dim_caps, routings=3): |
参数定义如下:
- in_num_caps:输入胶囊的数量
- in_dim_caps:输入胶囊的长度(维数)
- out_num_caps:输出胶囊的数量
- out_dim_caps:输出胶囊的长度(维数)
- routings:动态路由迭代的次数
另外,还定义了权值weight,尺寸为[out_num_caps, in_num_caps, out_dim_caps, in_dim_caps],即每个输出和每个输出胶囊都有连接
前向传播
1 | def forward(self, x): |
前向传播分为两个部分:输入映射和动态路由。输入映射如下所示:
x_hat = torch.squeeze(torch.matmul(self.weight, x[:, None, :, :, None]), dim=-1)x[:, None, :, :, None]将数据维度从[batch, in_num_caps, in_dim_caps]扩展到[batch, 1,in_num_caps, in_dim_caps,1]torch.matmul()将weight和扩展后的输入相乘,weight的尺寸是[out_num_caps, in_num_caps, out_dim_caps, in_dim_caps],相乘后结果尺寸为[batch, out_num_caps, in_num_caps,out_dim_caps, 1]torch.squeeze()去除多余的维度,去除后结果尺寸[batch,out_num_caps,in_num_caps,out_dim_caps]
x_hat_detached = x_hat.detach()截断梯度反向传播
这一部分结束后,每个输入胶囊都产生了out_num_caps个输出胶囊,所以目前共有in_num_caps*out_num_caps个胶囊,第二部分是动态路由,动态路由的算法图如下所示:

以下部分实现了该过程:
1 | b = Variable(torch.zeros(x.size(0), self.out_num_caps, self.in_num_caps)).cuda() |
- 第一部分是softmax函数,使用
c = F.softmax(b, dim=1)实现,该步骤不改变b的尺寸 - 第二部分是计算路由结果:
outputs = squash(torch.sum(c[:, :, :, None] * x_hat, dim=-2, keepdim=True))c[:, :, :, None]扩展c的维度,以便按位置相乘时广播维度torch.sum(c[:, :, :, None] * x_hat, dim=-2, keepdim=True)计算出每个胶囊与对应权值的积,即算法中的$s_j$,同时在倒数第二维上求和,则该步输出的结果尺寸为[batch, out_num_caps, 1,out_dim_caps]- 通过激活函数
squash()
- 第三部分更新权重
b = b + torch.sum(outputs * x_hat_detached, dim=-1),两个按位相乘的变量尺寸分别为[batch, out_num_caps, in_num_caps, out_dim_caps]和[batch, out_num_caps, 1,out_dim_caps],倒数第二维上有广播行为,因此最终结果为[batch, out_num_caps, in_num_caps]
其他组件
网络结构
1 | class CapsuleNet(nn.Module): |
网络组件包括两个部分:胶囊网络和重建网络,重建网络为多层感知机,根据胶囊的结果重建了图像,这表示胶囊除了包括结果外,还可以包括一些空间信息。
注意胶囊网络的前向传播部分为:
1 | x = self.relu(self.conv1(x)) |
最终的输出为每个胶囊的二范数,即向量的长度
代价函数
胶囊神经网络的胶囊部分的代价函数如下所示
以下代码实现了这个部分,其中L为胶囊的代价函数计算,这里$m^+=0.9,m^-=0.1$,L_recon为重建的代价函数,为输入图像与复原图像的MSELoss函数。
1 | def caps_loss(y_true, y_pred, x, x_recon, lam_recon): |
