1 | import mxnet as mx |
官方github教程部分代码
网络生成
1 | num_layers = 2 |
mx.rnn.SequentialRNNCell():RNN容器,用于组合多个RNN层mx.rnn.LSTMCell(num_hidden=num_hidden, prefix='lstm_l%d_'%i):LSTM单元
1 | num_embed = 256 |
(<Symbol softmax>, ('data',), ('softmax_label',))
unroll()函数按时间展开RNN单元,输出最终的运算结果- 输出接全连接层,再转换为词向量
官方API文档代码
数据转换
1 | step_input = mx.symbol.Variable('step_data') |
Embedding是一种词向量化技术,这种技术可以保持语义(例如相近语义的词的向量距离会较近),将尺寸为(d0,d1…dn)的输入向量进行词向量化技术后转换为尺寸为(d0,d1,…,dn,out_dim)的向量,多出的一维为词向量,即使用一个向量代替原来一个词的位置。
- 参数input_dim为输入向量的范围,即输入data的范围在[0,input_dim)之间
- 参数output_dim为词向量大小
- 可选参数weight,可传入指定的词向量字典
- 可选参数name,可传入名称
1 | vocabulary_size = 26 |
([(10, 64), (26, 16)], [(10, 64, 16)], [])
上文的例子可以看出输入向量尺寸为(10,64),输出向量尺寸变为了(10,64,16)
网络构建
使用了隐层为50的LSTM单元,并带入转换好的数据,该图绘制出的lstm图较经典LSTM有一些出入
1 | lstm_cell = mx.rnn.LSTMCell(num_hidden=50) |
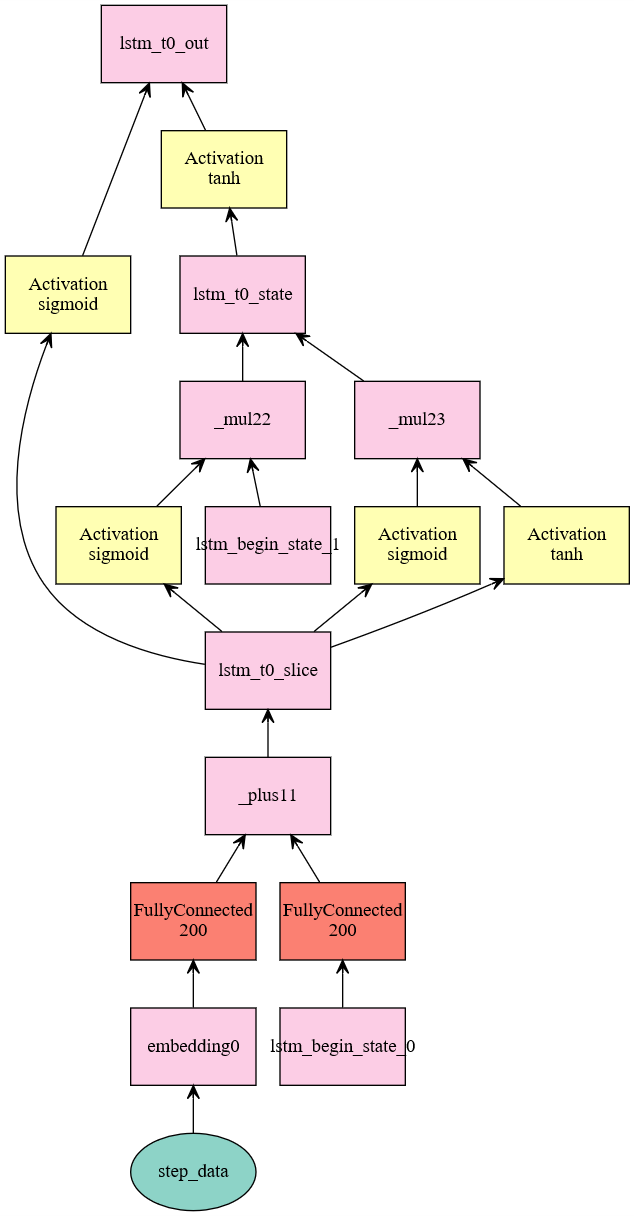
LSTM的源码的构造函数如下:1
2
3
4
5
6
7
8
9def __init__(self, num_hidden, prefix='lstm_', params=None, forget_bias=1.0):
super(LSTMCell, self).__init__(prefix=prefix, params=params)
self._num_hidden = num_hidden
self._iW = self.params.get('i2h_weight')
self._hW = self.params.get('h2h_weight')
# we add the forget_bias to i2h_bias, this adds the bias to the forget gate activation
self._iB = self.params.get('i2h_bias', init=init.LSTMBias(forget_bias=forget_bias))
self._hB = self.params.get('h2h_bias')
其中:self.params.get()方法为尝试找到传入名称对应的Variable,若找不到则新建,因此该LSTM单元一共仅有两对参数:iW和iB,hW和hB
前向传播函数如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def __call__(self, inputs, states):
self._counter += 1
name = '%st%d_'%(self._prefix, self._counter)
i2h = symbol.FullyConnected(data=inputs, weight=self._iW, bias=self._iB,
num_hidden=self._num_hidden*4,
name='%si2h'%name)
h2h = symbol.FullyConnected(data=states[0], weight=self._hW, bias=self._hB,
num_hidden=self._num_hidden*4,
name='%sh2h'%name)
gates = i2h + h2h
slice_gates = symbol.SliceChannel(gates, num_outputs=4,name="%sslice"%name)
in_gate = symbol.Activation(slice_gates[0], act_type="sigmoid",name='%si'%name)
forget_gate = symbol.Activation(slice_gates[1], act_type="sigmoid",name='%sf'%name)
in_transform = symbol.Activation(slice_gates[2], act_type="tanh",name='%sc'%name)
out_gate = symbol.Activation(slice_gates[3], act_type="sigmoid",name='%so'%name)
next_c = symbol._internal._plus(forget_gate * states[1], in_gate * in_transform,name='%sstate'%name)
next_h = symbol._internal._mul(out_gate, symbol.Activation(next_c, act_type="tanh"),name='%sout'%name)
return next_h, [next_h, next_c]
可以看出,LSTM的实现过程如下所示
- 计算隐层输入与状态,隐层的channel数量是配置的hidden_num的四倍
- 将隐层输入结果和隐层状态相加,并按channel数量切分为4份
- 第一份作为输入门层,经过sigmoid函数
- 第二份作为忘记门层,经过sigmoid函数
- 第三份作为输入转换层,经过tanh函数
- 第四份作为输出门层,经过sigmoid函数
- 产生输出
- 输出状态为忘记门层乘状态的一部分加输入门层乘输入转换层
- 输出结果为输出状态经过tanh乘输出门层
结果生成
1 | sequence_length = 10 |
使用unroll方法按时间展平运算,输入数据为(batch_size,lenght,…)(layout=”NTC)或(lenght,batch,…)(layout=”TNC)
该函数的源码为:
1 | def unroll(self, length, inputs, begin_state=None, layout='NTC', merge_outputs=None): |
方法_normalize_sequence是对输入做一些处理,由一个for循环可以看出该方法循环了网络运算
