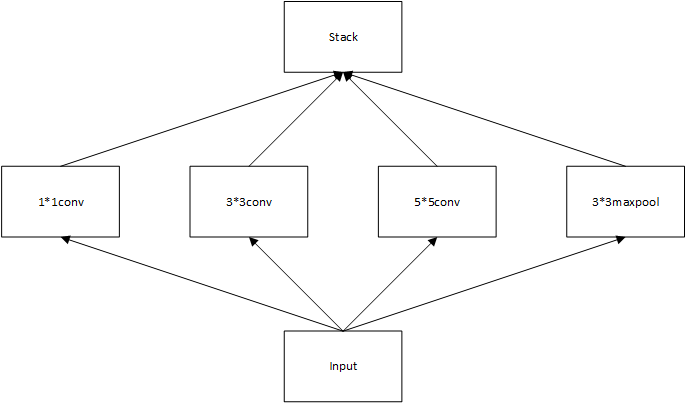
Inception结构 初级Inception 结构 初级Inception结构如下所示:
其前向传播分为4个部分:
通过1x1卷积
通过3x3卷积,padding为1(不改变图片大小)
通过5x5卷积,padding为2(不改变图片大小)
通过3x3池化,为了保证图片大小与以上相同,stride应为1,padding应为1
最后,将以上四个部分在feature这一维度堆叠起来,即获得最终输出
分析 假设输入feature,每个层(卷积和池化)输出feature分别为$N_i,N_o$(即最终输出feature为$4 \times N_o$);输入图片的尺寸为WxL,对于每一层,有:
1x1卷积层:有参数$1 \times 1 \times N_i \times N_o = N_iN_o$,需要进行计算的次数为$N_o \times W \times L \times 1 \times 1 \times N_i = WLN_iN_o$
3x3卷积层:有参数$3 \times 3 \times N_i \times N_o = 9N_iN_o$,需要计算次数为$N_o \times W \times L \times 3 \times 3 \times N_i = 9WLN_iN_o$
5x5卷积层,同上,参数为$25N_iN_o$,需要计算次数为$25WLN_iN_o$
因此,总的参数量为$(1+9+25)N_iN_o = 35N_iN_o$,需要的运算量为$(1+9+25)WLN_iN_o = 35WLN_iN_o$。考虑一个输入输出相同尺寸的3x3卷积,需要的参数量为$3 \times 3 \times N_i \times 4N_o = 36N_iN_o$,需要的运算量是$4N_o \times W \times L \times 3 \times 3 \times N_i = 36WLN_iN_o$,可以发现该结构在运算量和参数量近乎不变的情况下实现了多种感受野的连接。
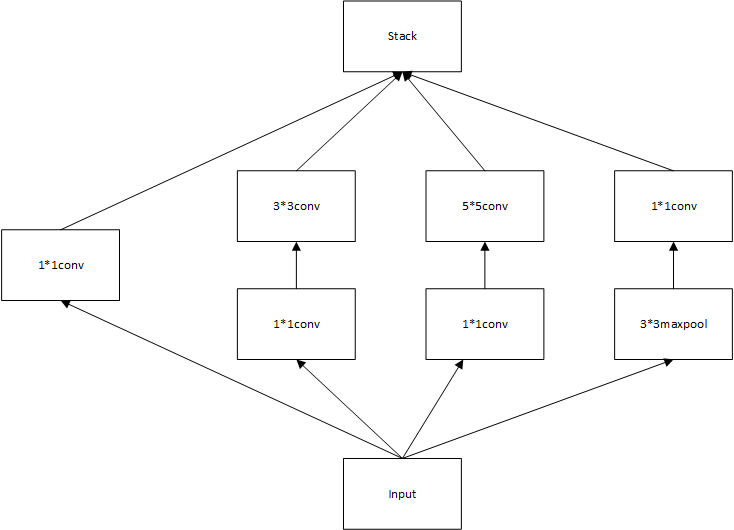
改进Inception结构 结构 改进的Inception结构如下图所示
同样具有四条前向传播通路,如下所示:
1x1卷积
先通过1x1卷积降维,再通过3x3卷积
先通过1x1卷积降维,再通过5x5卷积
先通过3x3maxpool,再通过1x1调整维度
最后,将以上四个部分在feature这一维度堆叠起来,即获得最终输出
分析 假设同上一部分,假设每个降维将降维降到原来维度的一半,对每一部分有如下所示:
每个降维的1x1层,需要的参数量是$\cfrac{1}{2}N_i^2$,运算参数量$\cfrac{1}{2}WLN_i^2$
1x1卷积层:有参数$1 \times 1 \times \cfrac{1}{2}N_i \times N_o = \cfrac{1}{2}N_iN_o$,需要进行计算的次数为$N_o \times W \times L \times 1 \times 1 \times \cfrac{1}{2}N_i = \cfrac{1}{2}WLN_iN_o$
3x3卷积层:有参数$3 \times 3 \times \cfrac{1}{2}N_i \times N_o = 9N_iN_o$,需要计算次数为$N_o \times W \times L \times 3 \times 3 \times \cfrac{1}{2}N_i = \cfrac{9}{2}WLN_iN_o$
5x5卷积层,同上,参数为$\cfrac{25}{2}N_iN_o$,需要计算次数为$\cfrac{25}{2}WLN_iN_o$
假设$N_i = N_o$,参数量一共是$3 \times \cfrac{1}{2}N_i^2 + \cfrac{35}{2}N_i^2 = 19N_i^2$,需要运算的数量为$19WLN_i^2$。可以发现无论是运算量还是参数量都小于原结构
代码 1 2 import mxnet as mximport numpy as np
Inception结构搭建 Inception结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class inception (mx.gluon.Block ): def __init__ (self,out_channel ): super (inception,self).__init__() with self.name_scope(): self.conv1 = mx.gluon.nn.Conv2D(out_channel,1 ,activation='relu' ) self.conv3_pre = mx.gluon.nn.Conv2D(out_channel//2 ,1 ) self.conv3 = mx.gluon.nn.Conv2D(out_channel,3 ,activation='relu' ,padding=1 ) self.conv5_pre = mx.gluon.nn.Conv2D(out_channel//2 ,1 ) self.conv5 = mx.gluon.nn.Conv2D(out_channel,5 ,activation='relu' ,padding=2 ) self.pool_post = mx.gluon.nn.Conv2D(out_channel,1 ,activation='relu' ) self.pool = mx.gluon.nn.MaxPool2D(pool_size=3 ,strides=1 ,padding=1 ) def forward (self,x ): result = [ self.conv1(x), self.conv3(self.conv3_pre(x)), self.conv5(self.conv5_pre(x)), self.pool_post(self.pool(x))] return mx.ndarray.concat(dim=1 ,*result)
Inception结构测试 1 2 3 inception_model = inception(10 ) print(inception_model) inception_model.collect_params().initialize(mx.init.Normal(sigma=.1 ), ctx=mx.gpu())
inception(
(pool_post): Conv2D(None -> 10, kernel_size=(1, 1), stride=(1, 1))
(pool): MaxPool2D(size=(3, 3), stride=(1, 1), padding=(1, 1), ceil_mode=False)
(conv1): Conv2D(None -> 10, kernel_size=(1, 1), stride=(1, 1))
(conv3): Conv2D(None -> 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv5_pre): Conv2D(None -> 5, kernel_size=(1, 1), stride=(1, 1))
(conv5): Conv2D(None -> 10, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(conv3_pre): Conv2D(None -> 5, kernel_size=(1, 1), stride=(1, 1))
)
1 2 indata = mx.ndarray.zeros((1 ,5 ,10 ,10 ),mx.gpu()) inception_model(indata).shape
(1, 40, 10, 10)
整体网络结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class network (mx.gluon.Block ): def __init__ (self ): super (network,self).__init__() with self.name_scope(): self.conv1 = mx.gluon.nn.Conv2D(channels=8 ,kernel_size=3 ,padding=1 ) self.conv2 = inception(8 ) self.conv3 = inception(16 ) self.conv4 = inception(16 ) self.fc = mx.gluon.nn.Dense(10 ) self.pool = mx.gluon.nn.MaxPool2D(pool_size=3 ,strides=2 ) def forward (self,x ): x = self.conv2(self.conv1(x)) x = self.conv3(self.pool(x)) x = self.conv4(self.pool(x)) return self.fc(x)
1 2 3 model = network() print(model) model.collect_params().initialize(mx.init.Normal(sigma=.1 ), ctx=mx.gpu())
network(
(pool): MaxPool2D(size=(3, 3), stride=(2, 2), padding=(0, 0), ceil_mode=False)
(conv1): Conv2D(None -> 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv3): inception(
(pool_post): Conv2D(None -> 16, kernel_size=(1, 1), stride=(1, 1))
(pool): MaxPool2D(size=(3, 3), stride=(1, 1), padding=(1, 1), ceil_mode=False)
(conv1): Conv2D(None -> 16, kernel_size=(1, 1), stride=(1, 1))
(conv3): Conv2D(None -> 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv5_pre): Conv2D(None -> 8, kernel_size=(1, 1), stride=(1, 1))
(conv5): Conv2D(None -> 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(conv3_pre): Conv2D(None -> 8, kernel_size=(1, 1), stride=(1, 1))
)
(conv2): inception(
(pool_post): Conv2D(None -> 8, kernel_size=(1, 1), stride=(1, 1))
(pool): MaxPool2D(size=(3, 3), stride=(1, 1), padding=(1, 1), ceil_mode=False)
(conv1): Conv2D(None -> 8, kernel_size=(1, 1), stride=(1, 1))
(conv3): Conv2D(None -> 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv5_pre): Conv2D(None -> 4, kernel_size=(1, 1), stride=(1, 1))
(conv5): Conv2D(None -> 8, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(conv3_pre): Conv2D(None -> 4, kernel_size=(1, 1), stride=(1, 1))
)
(fc): Dense(None -> 10, linear)
(conv4): inception(
(pool_post): Conv2D(None -> 16, kernel_size=(1, 1), stride=(1, 1))
(pool): MaxPool2D(size=(3, 3), stride=(1, 1), padding=(1, 1), ceil_mode=False)
(conv1): Conv2D(None -> 16, kernel_size=(1, 1), stride=(1, 1))
(conv3): Conv2D(None -> 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv5_pre): Conv2D(None -> 8, kernel_size=(1, 1), stride=(1, 1))
(conv5): Conv2D(None -> 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(conv3_pre): Conv2D(None -> 8, kernel_size=(1, 1), stride=(1, 1))
)
)
1 2 3 ```python indata = mx.ndarray.zeros((1 ,1 ,28 ,28 ),mx.gpu()) model(indata).shape
(1, 10)
训练准备 数据集——MNIST数据集 1 2 3 4 def transform (data, label ): return mx.nd.transpose(data,axes=(2 ,0 ,1 )).astype(np.float32)/255 , label.astype(np.float32) gluon_train_data = mx.gluon.data.DataLoader(mx.gluon.data.vision.MNIST(train=True , transform=transform),100 , shuffle=True ) gluon_test_data = mx.gluon.data.DataLoader(mx.gluon.data.vision.MNIST(train=False , transform=transform),100 , shuffle=False )
代价函数——交叉熵 1 softmax_cross_entropy = mx.gluon.loss.SoftmaxCrossEntropyLoss()
优化器——sgd 1 trainer = mx.gluon.Trainer(model.collect_params(), 'sgd' , {'learning_rate' : .1 })
准确率计算 1 2 3 4 5 6 7 8 9 10 def evaluate_accuracy (model ): acc = mx.metric.Accuracy() for i, (data, lable) in enumerate (gluon_test_data): data = data.as_in_context(mx.gpu()) lable = lable.as_in_context(mx.gpu()) output = model(data) predictions = mx.nd.argmax(output, axis=1 ) acc.update(preds=predictions, labels=lable) return acc.get()[1 ] evaluate_accuracy(model)
0.050200000000000002
训练 1 2 3 4 5 6 7 8 9 10 11 for _ in range (2 ): for i,(data,lable) in enumerate (gluon_train_data): data = data.as_in_context(mx.gpu()) lable = lable.as_in_context(mx.gpu()) with mx.autograd.record(): outputs = model(data) loss = softmax_cross_entropy(outputs,lable) loss.backward() trainer.step(data.shape[0 ]) if i % 100 == 1 : print(i,loss.mean().asnumpy()[0 ])
1 0.16968
101 0.104242
201 0.093354
301 0.07079
401 0.123301
501 0.086882
1 0.0325385
101 0.0510763
201 0.0242231
301 0.0454984
401 0.0788167
501 0.0591589
1 evaluate_accuracy(model)
0.98829999999999996